Optional: Optimize
In this step you can have your PDF documents improved by text recognition or other options.

Perform text recognition
If this option is enabled, scanned image pages are searched for text and the text is placed invisibly over the image - the page is thus searchable.
The text can then be searched for in the documents and the user can jump to the respective hits. If an indexing system (document management system, Windows Explorer, or similar) is used, the contents of several files can be searched simultaneously.
All incoming PDF documents are analyzed and made searchable. This also applies to pages that are subsequently stored in the error folder. Text recognition is only applied to "image-only" pages - vectorized pages are skipped. Since the individual pages of the document must be modified during this process, any signatures or PDF/A certifications are automatically removed from the document before the process.
Multiple languages are supported, select the languages you want to recognize. Depending on the number of languages, this will affect the processing speed.
First convert all pages into an image graphic and apply text recognition to all pages
If vectorized pages are also to be searched for text, you can activate this option. This converts the incoming document into an image and the text recognition is then performed on all pages.
If you activate this function, you can also apply various optimizations (these change the source image)
| Correct inverted graphics | Corrects inverted colors (background black, text white) |
| Remove Color Noise | Removes image information and reduces the number of colors and grayscales used to achieve better compression |
| Despecle | Removes image noise |
| Remove punch holes | Removes "black" holes at the edges |
| Optimize page border | Optimizes frayed image margins, or scan errors with wavy paper |
| Deskew pages | Tries to correct if scanned documents are fed 'slightly skewed' from the scanner and straightens them |
| Convert to gray | Converts the document to grayscale |
| Convert to B/W | Converts the document to black and white |
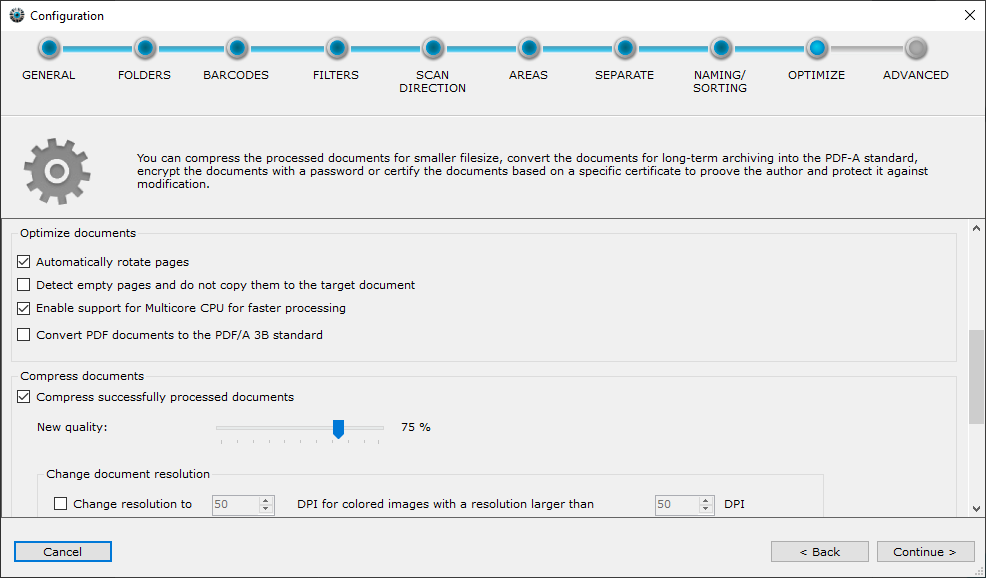
Rotate pages automatically according to the font direction
If activated, individual pages of the document are rotated by 90°, 180° or 270°. Thus, it is not necessary to manually rotate individual pages in the document stack in order to read them.
This option is applied after barcode recognition. Note that the scanning direction of the barcodes (step 5) is performed before the automatic rotation.
Remove blank pages from scanned documents
Pages with little image information can be automatically removed when processing the documents. For each image, a factor is determined how much image information is present and what the ratio is. If too little image information is available, the page is not transferred to the target document and is deleted. A value of 0.02 is preset.
You can use a sample scan (with blank pages) to calibrate the value individually per work instruction. All pages of the selected PDF document are analyzed and the value is determined for each page. The lowest value from the document is then set as the new threshold value. You can also adjust it manually. Pages with a lower factor will not be included in the target document and will be deleted.
Support for multiple processor cores for faster processing of documents
This results in a more optimal utilization of several processor cores. If this option is activated, up to 16 processor cores are automatically loaded.
PDF/A
If you want to save your PDF documents for long-term archiving, activate this option. You can select, in which exact standard you would like to convert the input files. The following options are available:
- PDF/A-1u
- PDF/A-1b
- PDF/A-2a
- PDF/A-2u
- PDF/A-2b
- PDF/A-3a
- PDF/A-3u
Please note that the file size of PDF/A files is usually larger. This is due to the fact that fonts and other metadata are stored in the document.
Compress PDF documents
In this case, graphics within the documents are reduced in quality to reduce the file size. Based on the current graphics quality, you can reduce the graphics by a certain percentage. Depending on the graphic format, a quality of 75-90% is a good compromise between graphic quality and file size. The compression level of the documents depends on the graphics embedded within the PDF file. Compression is lossy, which means that image information is removed from the graphics.
Your scanner scans the documents in a certain resolution (e.g. 200 or 300 DPI). The higher the resolution of the documents, the better barcodes can be recognized and the larger the documents are in file size. If a high resolution is necessary for reliable barcode recognition, but the documents are not archived in the resolution, the resolution can be reduced.
This has a significant effect on the size of the incoming files. You can define this separately by type (color, grayscale or b/w) and also define the resolution from which the reduction should take place first.
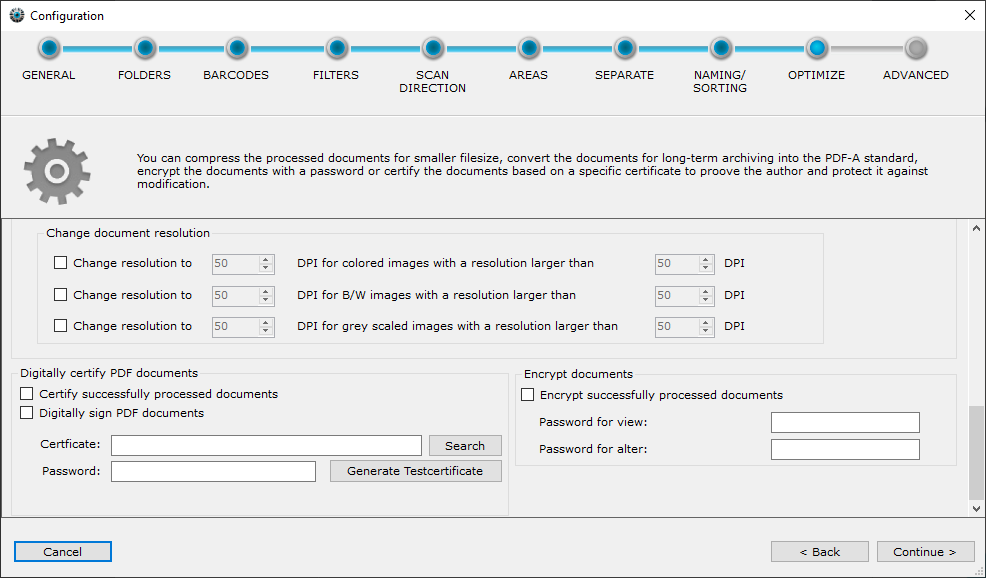
Digitally sign & certify PDF documents
With the help of a digital certificate, PDF documents receive an invisible digital signature when saved in the output folder. The document can then be annotated or edited. However, the signature is then no longer valid because the document was subsequently modified. With the signature it is possible to display the original version of the document again.
An X.509 certificate and the corresponding private key in a PKCS#12 file is required. (for example .p12 or .pfx file). These certificates can also be created by the user or purchased from a CA.
If you want to use an existing certificate, click on "Search" and select the certificate. Then enter the password to open the certificate file. This is mandatory and will be checked when clicking on "Next >". If you have entered an incorrect password or the certificate for the digital signature is not compatible, you will receive a message.
For testing purposes, it is possible to generate a compatible test certificate. To do this, click on "Generate test certificate".
In addition, a timestamp (via a timestamp server) can be added to the signature. Time stamp servers that comply with the RFC3161 standard are supported. If the time stamp server requires access data, these can also be stored.
Encryption
You can encrypt documents with secure symmetric AES encryption. To do so, define a password for opening the document (read mode) and a password for write mode (including removing the encryption). Documents in the error and output folder are then stored encrypted during processing by BarcodeOCR.
When opening the file in your PDF viewer you will be asked for the password. The content of the document can only be displayed after the password has been entered.
BarcodeOCR cannot process encrypted documents. If you store an encrypted file in the input folder of a work instruction, the file will be moved to the error folder and not processed.