Erkennung
Erkennung eines Barcodes in einer vektorisierten Datei
Es gibt zwei Arten von PDF-Dokumenten, zwischen die im Rahmen der Erkennung unterschieden werden muss:
| Eigenschaft | Bild-PDF-Datei | vektorisierte PDF-Datei |
|---|---|---|
| Zusammenfassung | Jede Seite hat ein "Bild", welches die Seite zu 100% abdeckt. Es sind keine weitere Elemente auf einer Seite vorhanden | Jede Seite kann mehrere unterschiedliche Elemente haben: Text, Bilder, Formulare, Barcodes (als Text oder als Bild) |
| Elemente pro Seite | Nur 1 | 0 oder mehr |
| Vergleichbar mit | Einem Foto von Text und Grafiken:
| Einer Internetseite:
|
Wie erkenne ich, ob meine Barcodes vektorisiert sind?
| Beispiel | Erklärung |
|---|---|
|
In diesem Beispiel sind bestimmte Bereiche bedeutend dunkler und schärfer (rot markiert) |
|
|



Wie kann ich dieses Erkennungsproblem lösen?
Die Standardkonfiguration von BarcodeOCR ist für die Erkennung einer Bild-PDF-Datei optimiert und ließt damit nur eine Ebene. Vektorisierte PDF-Dateien werden damit in der Regel nicht erkannt, da der Barcode auf mehreren Ebenen liegen könnte.
Unsere Software würde dann - wenn überhaupt - nur einen kleinen des Barcodes sehen, welcher unvollständig und damit nicht lesbar ist.
Eine Prüfung eines Screenshots des Bildes, oder via einem Smartphone mit QR-Code-Scanner ist in diesem Fall nicht aussagekräftig, da der Barcode korrekt angezeigt wird, da der PDF-Reader diese bereits rendert und alle Ebenen anzeigt.
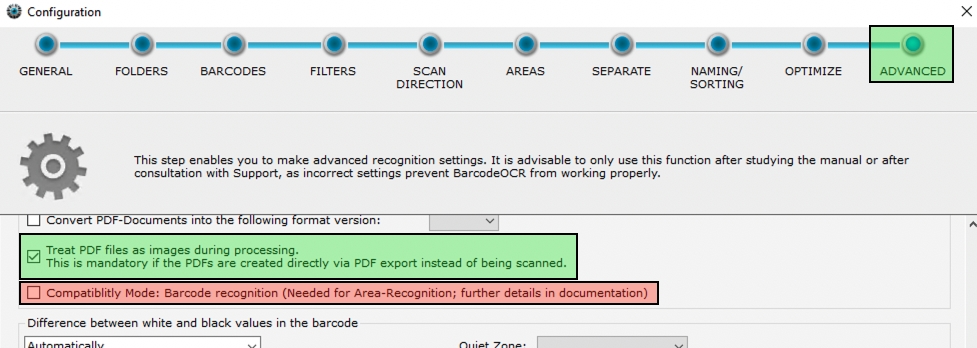
BarcodeOCR bietet für die Erkennung zwei verschiedene Optionen, die pro Arbeitsanweisung gesetzt werden müssen.
- Bei den meisten Dokumenten ist es bereits ausreichend, die grüne Option zu setzen - BarcodeOCR ließt in dem Fall alle Ebenen
- Hilft dies nicht, kann Alternativ die rote Option genutzt werden. Diese rendert zeitaufwändig jede Seite zu einem Bild und analysiert es.